- 16 april 2020
- Door Sammy Soetaert
- | 9 min. leestijd
- | Bron: Motion Control
VAN DATATSUNAMI NAAR OPTIMALISATIE MACHINEPRESTATIE
Offline data-analyse mogelijk
De analyse van uw data lijkt nieuwe opportuniteiten te openen voor uw productieproces, voornamelijk voor het opvolgen van de prestaties van uw machines. U kunt die analyse zelf doen, maar ook externe firma's kunnen deze taak van u overnemen. Maar hoe veilig is dat? En hoe optimaliseert u die stroom aan informatie? In twee delen nemen we u mee in de theorie en praktijk van dataverwerking. Eerst de theorie. In deel 2 van dit artikel gaan we in op de praktische kant van de zaak.

IN DE CLOUD? NIET NOODZAKELIJK!
Er was eens een productiechef die helemaal in het Industry 4.0-verhaal gezogen werd. Alle data van de sensoren zouden in de cloud geanalyseerd worden dankzij slimme algoritmes, machines zouden proactief kunnen reageren op nieuwe situaties en zelfstandig beslissingen nemen dankzij artificiële intelligentie. Het gevolg zou een vlekkeloos gestroomlijnde productie zijn, waarbij operatoren in real time alle prestaties en gegevens kunnen volgen op om het even welk communicatiemiddel. Dolenthousiast legde hij zijn plan voor aan de directie. Op de verwachte kritiek - dat zal te veel kosten - had hij zijn repliek al klaar: de flexibele productie zou klanten als muziek in de oren klinken, het monitoren van sensorgegevens zou via predictief onderhoud de uptime verhogen. Dankzij de data zou ook het energieverbruik geoptimaliseerd kunnen worden. De investering zou dus snel teruggewonnen zijn ... Toch raakte hij niet verder dan twee slides op zijn presentatie. Toen het woord 'cloud' viel, werd het plan afgeschoten en de meeting afgeblazen. De cloud wordt door directies en IT-diensten vaak gezien als het paard van Troje. Visioenen van hackende Russen en Chinezen die het gemunt hebben op onze dierbare data, worden op het netvlies gebrand en lijken daar moeilijk van af te halen. Doembeelden van op hol geslagen robots in een manloze productiehal worden afgewisseld met ingebeelde confrontaties met gefrustreerde arbeiders die vrezen voor hun job, nu artificiële intelligentie hun beslissingsrecht overneemt. Uiteraard is dit een pastiche en zal het in de realiteit niet zo'n vaart lopen, maar het geeft wel de richting aan waarin we ons stilaan begeven: de productiemanager wil volop genieten van innovaties, maar de directie en andere afdelingen willen om financiële of (cyber)veiligheidsredenen niet meteen meestappen in het verhaal. En dat is jammer, want data-analyse kan wel degelijk nuttig én veilig verlopen. Bovendien hoeft data-analyse helemaal niet cloudgebaseerd te zijn en kan het proces zelfs helemaal offline én binnen de muren van het bedrijf blijven.
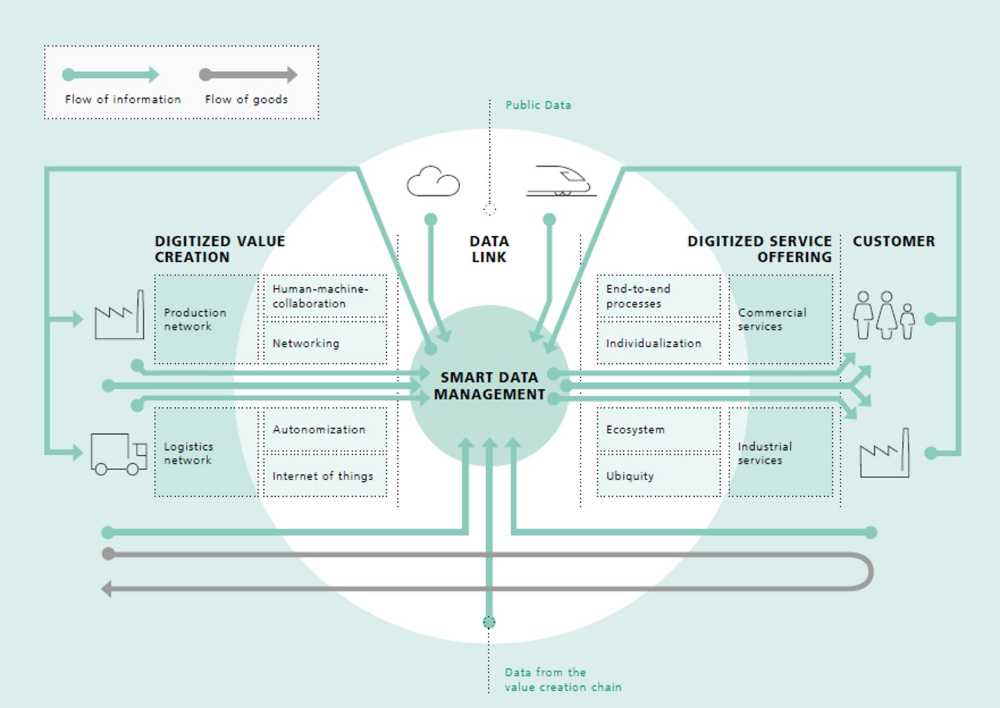
WELKE DATA ZIJN INZETBAAR?
In de grote textielfabrieken maakten vanaf eind 19e eeuw semiautomatische weefmachines hun intrede. Er heerste toen een schrijnend tekort aan arbeidskrachten en dankzij innovaties kon één wever meerdere machines tegelijk bedienen. De keerzijde van de medaille was dat een wever door zijn gestegen aantal machines niet langer potentiële problemen preventief kon aanvoelen bij élke machine. Daarom werden er machineknechten ingezet. Hun enige taak bestond erin om voortdurend de machines af te lopen en de mechaniek te controleren op anomalieën en deze te melden aan de opzichter. Toen was dat een revolutionair systeem, een eeuw later wordt deze taak overgenomen door sensoren. Bij motoren en pompen gaat het bijvoorbeeld over trillingen, temperatuur, druk, spanning, stroom, smeringskwaliteit en nog een rits andere mogelijkheden. Het gamma van sensoren is de voorbije jaren enorm uitgebreid, terwijl de prijzen kelderen. Het ligt dus binnen eenieders mogelijkheden om zijn machines te voorzien van sensoren. Maar data beperken zich niet tot meetgegevens uit sensoren. Ook externe technische machinegegevens, logfiles en procesdata uit frequentieregelaars en PLC's leveren een immense hoeveelheid bruikbaar materiaal op.
Tegelijkertijd zijn de middelen om de meetwaarden te communiceren met de gebruiker stelselmatig performanter geworden en via internet kan dat zelfs probleemloos wereldwijd gebeuren.
Procesanalyse
Als bedrijf kunt u meerdere zaken uit data halen. Een eerste is productieprocesanalyse en -verbetering. Via een audit van de data kan aangegeven worden waar de pijnpunten liggen en waar er ruimte voor verbetering ligt. Een eenvoudig voorbeeld is om via de analyse van temperatuurmetingen op een drive te bepalen waar zijn kritieke punt ligt, en om de productiesnelheid in functie van die analyse aan te passen.
Foutzoeken
Foutenanalyse is een tweede hoofdgroep. Als er ergens een fout zit in het productieproces, kan het foutzoeken zeer tijdrovend en frustrerend zijn. Als de fout bovendien niet gevonden wordt, kunnen de gevolgen desastreus zijn. Zeker in complexe processen is het moeilijk om correlaties en verbanden correct te analyseren. Een voorbeeld: er zijn grootheden die slechts tot op een zekere hoogte een positief lineair verband hebben. Zodra een van die grootheden een zekere drempelwaarde bereikt heeft, slaat dat verband om in een negatieve correlatie. Dat is voor de mens heel moeilijk te detecteren, en al zeker niet als er tientallen van die verbanden tegelijkertijd op elkaar inspelen. In een productieproces met dergelijke verbanden een minieme fout opsporen is in deze gevallen echt een speld-in-een-hooibergverhaal. De kracht van data-analyse kan hier soelaas bieden.
Anomaliedetectie
Niet alle fouten worden evenwel opgemerkt door mensen. Ongesuperviseerde anomalieën, dat zijn fouten die niet als dusdanig herkend werden door menselijke intelligentie, zijn uiteraard ongewenst. Om deze anomalieën te detecteren, kan er ook gebruikgemaakt worden van data-analyse. Eerst moet aangeleerd worden wat de normale patronen zijn van de installatie, volgens de variaties en de dynamiek van de installatie. Dat kunnen numerieke data zijn uit sensoren, maar ook logfiles uit machines. Die logfiles geven niet enkel info over de toestand, maar beschrijven ook wat ze exact aan het doen zijn. Vervolgens wordt de installatie op een statistische manier aangeleerd welke toestanden correct zijn en welke buiten de grenzen van het normale vallen. Dit soort systemen kan perfect binnen de muren van een bedrijf draaien en geïntegreerd worden met elk mogelijk datamonitoringplatform. Anomaliedetectie in datasets is echt specialistenwerk, het vergt gespecialiseerde software om anomalieën te detecteren. Het herkennen van een foutpatroon van één variabele is eerder eenvoudig, maar dat verandert als er meerdere variabelen in het spel zitten. Een verloop van één grootheid kan, indien apart bekeken, volledig normaal zijn. In relatie met het verloop van andere grootheden (multivariate) kan datzelfde patroon echter niet normaal zijn.
Een eenvoudig voorbeeld is een wielrenner. Een stijgende hartslag kan perfect binnen de grenzen van het normale vallen, bijvoorbeeld omdat de renner versnelt. Als er echter ook een sensor met de hoogtemeters aangesloten wordt, kan datzelfde stijgende hartritmepatroon echter vreemd zijn als de hoogtemetermeting in diezelfde tijdsspanne daalt. Ook bij machines speelt dit soort onderlinge relatie een zeer belangrijke rol. Er is hierbij niet enkel een belangrijke rol weggelegd voor de kennis van de installatie, ook de algoritmes binnen de software die de anomaliedetectie moet uitvoeren, moeten van topniveau zijn. Net hierin gebeuren er momenteel zeer interessante zaken, ook in ons land zijn we de trotse bezitter van enkele bedrijven die hier regelrechte voorlopers in zijn.

VIRTUELE SENSOREN
Niet elke grootheid kan zomaar gemeten worden met een fysieke sensor. Soms zijn de omstandigheden van die aard (vervuiling, hitte, vocht …) dat een fysieke sensor meteen stukgaat of tot een onnauwkeurige meting leidt. Een andere beperking om een fysieke sensor in te zetten, kan zijn kostprijs zijn. Bovendien zijn er grootheden die sowieso niet gemeten kunnen worden met een fysieke sensor. Hier kunnen data een oplossing bieden, door het creëren van virtuele sensoren. In dat geval worden er data ingezet om toch de gewenste grootheid te weten te komen. Dat doet men door wiskundige modellen los te laten op de wel beschikbare data. Die ingangsdata kunnen metingen zijn van andere grootheden, informatie uit databanken, parameters. Aan de uitgang krijgen we dan de weergave van een grootheid die niet via een fysieke sensor gemeten kon worden. Een vaak gebruikte toepassing van virtuele sensoren is het vermijden van destructieve labtesten. Een papiersterktetest is hier een prima voorbeeld van. Om de papiersterkte te meten, was enkel een destructieve meting mogelijk, waarbij door geregelde bemonstering de sterkte telkens gecontroleerd moet worden. Via virtual sensing worden meerdere proceseigenschappen zoals onder andere de dikte van het papier, de loopsnelheid van de machine, de druk en de temperatuur gemeten. Door deze data in een model te gieten, kan een benadering gemaakt worden van de sterkte die gemeten zou worden in het labo via een destructieve test. Door die resultaten ook nog eens te vergelijken met historische meetresultaten die onder dezelfde omstandigheden verkregen werden, kan er zo een zeer accuraat resultaat behaald worden. Andere grootheden die in de papierindustrie gemeten kunnen worden, zijn onder andere het vochtgehalte, het gramgewicht en de sterkte van het papier.
MET WIE GAAN WE IN ZEE?
De belangrijkste vraag is misschien nog:aan wie vertrouwt u uw data toe? Uw data zijn geld waard, laat dat volledig duidelijk zijn. Meerdere aanbieders van diverse oorsprong zijn er dan ook op uit om aan de slag te gaan met uw data.
We zien dat de grote softwarespelers genre Microsoft en IBM sterk inzetten op industriële cloudapplicaties en dat de grote spelers lanceringen in die richtingen doen (MindSphere van Siemens is een voorbeeld hiervan), maar het is ook waarschijnlijk dat er een tussenlaag zal ontstaan van bedrijven die hier een dienstverlening zullen aanbieden. Denk aan het filteren en klaarmaken van data voor ze effectief doorgestuurd worden, en het programmeren van bedrijfsspecifieke apps. Datamanagement zal in de toekomst dus zeer belangrijk worden.

DATA EFFICIENT INZETTEN
BEMONSTERING EN COMPRESSIE
Er ligt een enorm potentieel in uw data, maar de kunst is om deze efficiënt in te zetten. Daarom gingen we op de koffie bij Jan Verhasselt. Hij is bedrijfsleider van Yazzoom, een bedrijf actief in de optimalisatie van processen door het inzetten van data. We stelden hem enkele pertinente vragen rond deze materie.
Veel ondernemingen willen in wel iets aanvangen met hun data, maar weten vaak niet hoe te beginnen. Hebt u enkele tips?
of aan een externe factor?
“Alles begint met de doelstelling. Wat wil u exact bereiken met uw data? Wat is uw concrete nood? Van daaruit is het makkelijker te bepalen welke sensoren of welke logfiles vanuit machines ingezet moeten worden voor de analyse. Ook de benodigde samplefrequentie (om de hoeveel tijd u de gegevens verzamelt) zal blijken uit deze exacte doelstelling. De samplefrequentie heeft een rechtstreekse invloed op de datahoeveelheid en de prijs van de opslag. Ook de compressie is belangrijk: door data te veel of te snel gaan comprimeren, zal de data-analyse bemoeilijkt worden of zelfs tot een verkeerde conclusie leiden omdat bepaalde trends verdwenen zijn of onderbelicht worden. Een volgend vraagstuk is om de periode te bepalen waarmee men aan de slag wil gaan. Hoever moet je teruggaan in de tijd om een betrouwbaar model te realiseren? Kennis van de applicatie is ook hier weer van primordiaal belang, want bij bepaalde toepassingen is een sample van pakweg 10 ms voldoende omdat de volledige cyclustijd daarin al een aantal keer terugkomt en de toepassing ook zeer stabiel is. Aan de andere kant van het spectrum zitten dan weer zaken als seizoengebonden factoren. Als de schommelende buitentemperatuur meegenomen moet worden in een predictief model van pakweg een pomp, dan zal de sampletijduiteraard veel langer moeten zijn en eerder in termen van maanden of zelfs jaren verlopen. Ook andere variabele factoren die een invloed hebben op het proces, moeten meegenomen worden in de data-analyse. Het is dus zaak om de sampletijd zo te nemen dat alle variabele fenomenen die een invloed kunnen hebben op het productieproces, opgenomen worden in de berekeningen.“
KOSTPRIJS EEN HINDERPAAL?
Het lijkt voor kleinere bedrijven een onmogelijke opdracht om deze investering te doen. Correct?
“Dat klopt tot op zekere hoogte, maar het is zeker geen zwart-witverhaal. Er zijn start-ups die meteen op de kar springen, maar evengoed zijn er multinationals die deze concepten inzetten. Introspectie van het eigen bedrijf en de installatie is hier zeker aan te raden. Kan u met de analyse van uw data iets bereiken dat de investering rechtvaardigt? Een 'proof of concept', uitgevoerd door een gespecialiseerd bedrijf, kan u hier een eerste inschatting bezorgen. Uit de realiteit blijkt vaak dat de businesscases waarbij er voor een concreet probleem een oplossing gezocht wordt in data-analyse, de meest succesvolle output realiseren. Dit in tegenstelling tot de cases waarbij data zonder concrete aanleiding tegen het licht worden gehouden."
AANDACHT VOOR TOEKOMSTIGE ACTIES
Wat met bedrijven die bewust nog de kat uit de boom kijken? Laten zij kansen liggen?
“Data capteren vergt een inspanning naar opslag en hardware toe. Dat heeft ook een kostprijs, die bedrijven er soms van weerhoudt om de investering nu al te maken. In flexibele productieomgevingen zijn de doelstellingen van nu evenwel niet altijd gelijk aan die van morgen. Het is dus verstandig om vervangende acties nu al door te voeren met datacollectie in het achterhoofd. De meerprijs van een sensor of machine die hierop voorzien is, zal zich op termijn terugbetalen."
