- 29 mei 2019
- Door Dieter Devriendt
- | 5 min. leestijd
- | Bron: Motion Control
 EDGE COMPUTING
EDGE COMPUTING
Rekenwerk op de apparaten
In navolging van 'de cloud' maakt nu ook 'de edge' zijn opgang. Kort door de bocht: edge computing maakt gebruik van de rekencapaciteit van apparaten in een lokaal netwerk. Zo moeten de gegevens niet meteen richting cloud verstuurd worden, maar kunnen ze op het toestel zelf snel verwerkt worden. Dit biedt voordelen voor het nemen van realtimebeslissingen, het verhogen van de dataveiligheid en het besparen op tijd en middelen.
BEGRIPPEN
Een definitie van de begrippen is het begin van elke goede uitleg. Daarom eerst nog een kleine opfrissing van de volgende (al dan niet gekende) kernwoorden.
Cloud
Het bekendste begrip in deze lijst is ongetwijfeld 'de cloud'. In dit model worden intelligente taken uitgevoerd op servers die vervolgens doorgeven naar 'domme' apparaten.
Edge & edge computing
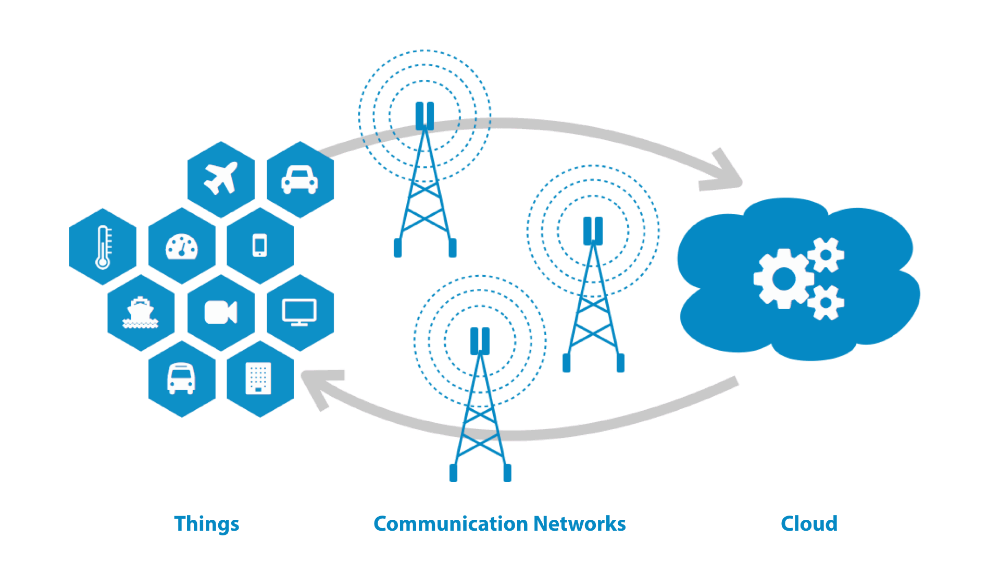
De 'edge' verwijst naar de uiterste grens van een informatietechnologienetwerk: de clients (app of systeem dat toegang heeft tot server via netwerk). Vaak zijn dit IoT (Internet of Things)-apparaten die de gegevens op het apparaat zelf verwerken eerder dan de sensorinfo naar de cloud sturen. 'Edge computing' slaat dan op het werk dat op deze apparaten wordt uitgevoerd; werk dat zo dicht mogelijk bij de brondata verricht wordt.
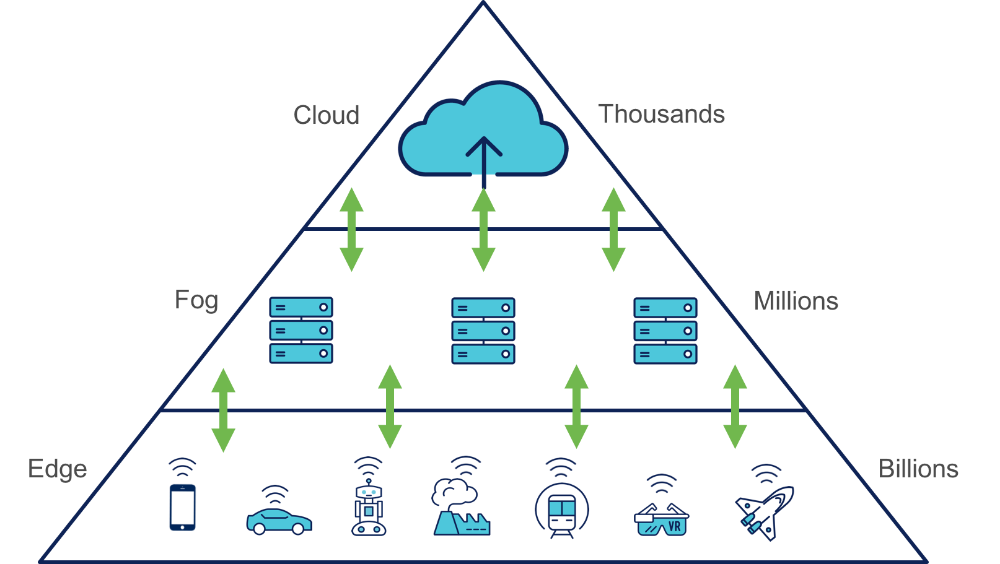
Dat biedt voordelen, niet enkel voor dataminimalisatie (niet alle ruwe data gaan in de cloud), maar ook voor zeer gedistribueerde systemen. Duizenden clients kunnen verbinden om allemaal stukjes werk te verrichten. Dat is het ideaalbeeld van edge computing: miljarden IoT-toestellen die een intelligent netwerk vormen dat taken uitvoert die anders enkel in een enorm datacenter kunnen gebeuren.
Combi edge-cloud
De combinatie tussen edge en cloud lijkt voor de hand liggend: de gedistribueerde systemen verwerken data op de toestellen zelf en sturen resultaten naar de cloud voor opslag en/of verdere analyse.
Edge vs. fog computing
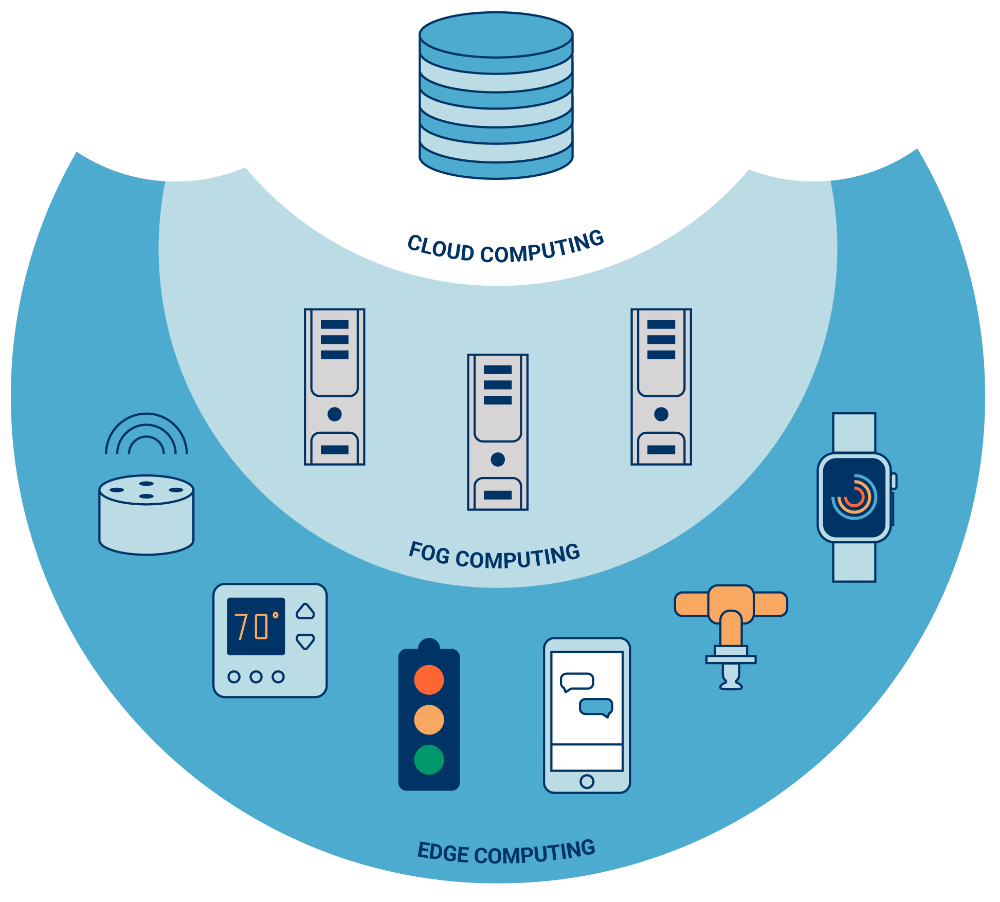
De trend naar decentralisatie van rekenkracht en opslag werd al een tijdje geleden ingezet. Decentrale intelligentie laat vaak efficiëntere acties toe en vermijdt onnodige kosten voor bandbreedte en opslag. In een beginfase werd met het vervagende onderscheid tussen cloud en lokaal het IT-landschap steeds mistiger, vandaar 'fog'. Waar de betrachting van edge en fog computing gelijkloopt - het gebruiken van rekencapaciteit in een lokaal netwerk waar dat normaliter uitgevoerd zou worden in de cloud - verschillen ze op het vlak van de plek waar de dataverwerking plaatsvindt. Edge computing komt gewoonlijk meteen voor op apparaten waarop sensoren bevestigd zijn of op een gatewaytoestel dat fysiek dicht bij sensoren geplaatst is. Fog computing, daarentegen, verschuift de rekenactiviteiten naar processoren (nodes) die LAN (local area network)-verbonden zijn of in de LAN-hardware zelf. Deze bevinden zich dus fysiek op meer afstand van de sensoren en actuatoren.
Combi fog-edge
Het combineren van fog en edge binnen één architectuur is dan wel mogelijk, maar de toepassingen zijn vrij zeldzaam, zeker in relatief kleine omgevingen. Fog heeft de mogelijkheden om zich in de gedistribueerde tussenlaag te gedragen als één systeem, dus deze aanpak is wel gepast bij situaties waarbij meerdere sites vanuit de cloud als één omgeving gezien moeten worden.
SLINGERBEWEGING: CENTRAAL?
De focus van informatietechnologie (IT) is sinds het ontstaan ervan aan het schommelen tussen centralisatie en decentralisatie. Het begon met gecentraliseerde mainframe computing. Vervolgens verschoof het zwaartepunt naar gedecentraliseerde client-servernetwerken. Met de cloud kwam weer een ommezwaai richting een gecentraliseerd model. Local computing - in edge of fog - grijpt terug naar het meer gedecentraliseerde model. Het gedecentraliseerde model is nodig omdat van IT-infrastructuur vandaag de dag verwacht wordt dat het een ruime waaier aan IoT-applicaties en -apparaten ondersteunt. De cloud is echter zeker niet afgeserveerd. Grote hoeveelheden data van traditionele IT-applicaties zullen wellicht hun verwerking in de cloud blijven vinden (vanwege de grote rekenkracht). Dat is echter voorbehouden voor data die geen directe aandacht vereisen; de verwerking van realtimebeslissingen gebeurt eerder in toestellen in de periferie. Als je de vergelijking maakt met een menselijk voorbeeld, is de cloud het brein, terwijl de edge en fog het zenuwstelsel zijn dat heel snel taken uitvoert, soms zelfs zonder terugkoppeling.
 EDGE-INFRASTRUCTUUR
EDGE-INFRASTRUCTUUR
Voor edge-infrastructuur zijn er een drietal vereisten die aanwezig moeten zijn.
Deel van gedistribueerde rekentopologie
Edge computing vereist een vorm van consistente, voldoende bandbreedte, lowpowerconnectiviteit.
Bluetooth is daarbij het meest voorkomend, maar mankeert consistentie. Wifi biedt een degelijke bandbreedte, maar de korte actieradius is erg nefast voor de consistentie en bovendien verbruikt die meer energie dan bluetooth.
Mobiele connectiviteit biedt de beste consistentie, maar heeft veel energie nodig en krijgt
af te rekenen met een soms beperkte bandbreedte. De ultieme oplossing lijkt 5G, met een laag energieverbruik, een betere dekking en een 100 keer grotere bandbreedte dan LTE (4G).
Informatieverwerking
De combinatie van hardware en software die informatie verwerken, is ook een vereiste. Afhankelijk van de complexiteit van de processen is een microcontroller unit (MCU) voldoende voor eenvoudige taken zoals datafiltering. Geavanceerde analyse en machinelearning vereisen dan weer de meer high-end central processing unit (CPU)/graphics processing unit (GPU) en opslag met ruimere capaciteit. De nood aan meer dynamic random-access memory (DRAM) is onvermijdbaar.
Gesitueerd dicht bij EDGE
'Dicht bij' de edge is een relatief begrip; het kan gaan van embedded intelligentie tot computing in eenzelfde regio.
Ter illustratie: voor autonoom rijden heeft edge computing sensoren in de wagen nodig om de chauffeur te monitoren vanaf het dashboard, maar eveneens sensoren die tot op 100 à 200 m rondom het voertuig detecteren.
Conclusie: 5G moet uitkomst bieden
Edge computing gaat niet simpelweg om situaties waarbij de informatieverwerking zich dicht bij de rand van een netwerk bevindt. Het wijst eerder op dataverwerking die zich uitstrekt van de kern tot de edge om te voldoen aan specifieke vereisten. Momenteel is de meeste infrastructuur voor edge computing ontworpen op enkel uitgaande contentflows (caching en outstreaming).
Een 5G-netwerk zal bijdragen tot het verminderen van de latentiebarrière en voldoende bandbreedte creëren. Betere software en processing units kunnen een verbetering voor de privacy en veiligheid meebrengen.
VOORDELEN EDGE COMPUTING
Veiligheid
Een van de grootste voordelen van edge computing is veiligheid, die hoger is omdat de data niet getransfereerd worden. Het apparaat dat de data 'creëerde', houdt de gegevens vast en verwerkt ze zelf.
Lage kosten
Een ander voordeel van edge computing is dat het helpt om de kosten laag te houden. De technologie bespaart op tijd en middelen bij onderhoudsoperaties door het verzamelen en analyseren van data in real time. Zo voorzien netwerken op de grens van het lokale netwerk bijnarealtimeanalyses die een optimalisatie van prestaties faciliteren en de uptime vergroten.
Evenwicht zoeken
Er is echter wel één minpuntje aan edge computing, namelijk de evenwichtsoefening tussen 'data in de edge houden' en 'de data naar de centrale cloud brengen wanneer nodig'. Bedrijven kunnen problemen hebben om te bepalen wanneer het ene dan wel het andere te prefereren is. Kostengewijs is het vaak efficiënter om de data lokaal te analyseren, maar dat is niet in alle gevallen zo. Datasets die meer gesofisticeerde algoritmes nodig hebben, kunnen beter behandeld worden in de cloud.
VOORDELEN FOG COMPUTING
Regionale opslag
Wanneer dataverwerking en gegevensopslag plaatsvinden in local area networks met fogcomputingarchitectuur, laat dat een organisatie toe om data van meerdere apparaten te verzamelen in regionale opslag.
Meer capaciteit
Fog computing laat toe om data van meerdere verschillende apparaten te verzamelen, en beschikt dus over een grotere capaciteit tot dataverwerking. Bovendien heeft de fog ook de capaciteit om realtime verzoeken te verwerken. Geen probleem dus om te implementeren wanneer miljoenen geconnecteerde apparaten gegevens uitwisselen.
Kost en consistentie?
De mogelijkheid om te verbinden met meer apparaten - en dus meer data te verwerken - dan edge computing is meteen ook een potentieel probleem voor fog computing.
Er is namelijk meer infrastructuur (investeringen!) nodig en men hangt ook af van de dataconsistentie over een heel omvangrijk netwerk.
